"Colourtext always take a fresh approach to discovering hidden patterns in data. Whether you want to conduct segmentation or mine your CRM for deep insights, they will help you see your customers , and what they are seeing , in new ways."

Analysing Twitter user data to target a brand's early adopters
Client: www.nuchido.com
Project: Using Twitter data to profile a competitor's early adopting customers
Project Design: Jason Brownlee, Colourtext
Data sources: Tweets from the Twitter Public API
This post is about how we developed a Twitter analytics process to discover the early adopters of a new health & well-being product and use this to build-out a broader look-a-like audience.
A health & beauty brand that we work with set out to launch a product into a new category. A competitor had already established itself and generated impressive sales, which was great because it proved customer demand was actually out there.
We set out to discover who the early adopters were that bought the competitor brand. But how can you do this when customer information is thin on the ground?

Here's something we tried that worked pretty well. Our client's competitor has around 10,000 followers on Twitter. We used Twitter's free Public API to drawn down the user profiles for each of our competitor's followers. This data usually contains a short personal description that people write about themselves in natural language.
This profile data is incredibly rich but can be difficult to analyse at scale because it's totally free-form and unstructured. However, there are a bunch of Natural Language Analysis techniques we can use to make this stuff useful.
We began by running all of the personal descriptions we got from Twitter's API through a semantic tagging app. This classified all of the different things people said about themselves into meaningful semantic categories such as Family, Information Technology, Science, Education, Art and Music etc.
After a little manual refinement we developed 40 bespoke semantic categories that were statistically significant within the personal descriptions of the early adopters who follow (and presumably buy) our competitor's product (see Chart 1).
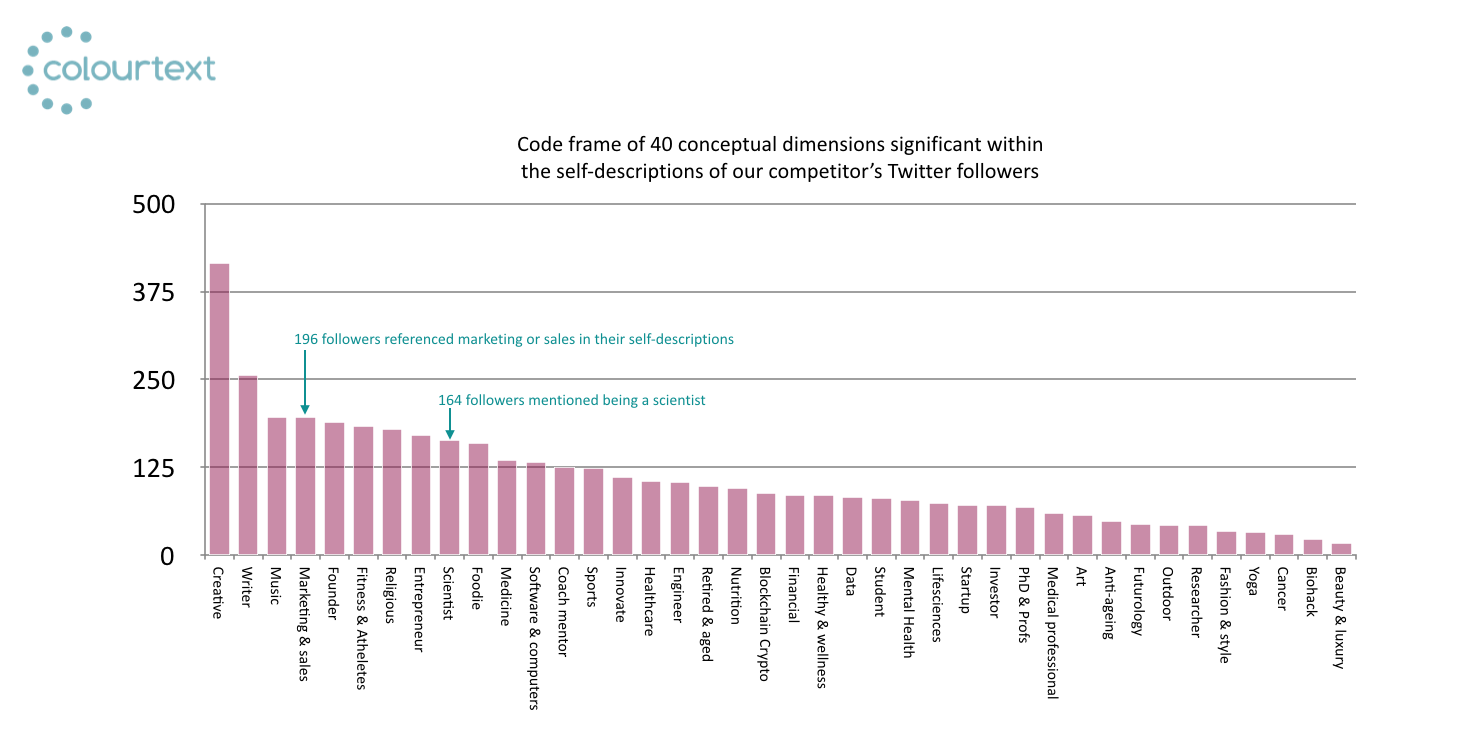
This information begins to paint a useful picture of the early adopters we're trying to reach and understand, but we can take the analysis further. We used a complex network segmentation analysis to group individuals into clusters based on the semantic tags that appeared in their self-descriptions. This yielded 9 early adopter customer segments with rich personality characteristics that our client can use to target their brand launch proposition (see Chart 2).
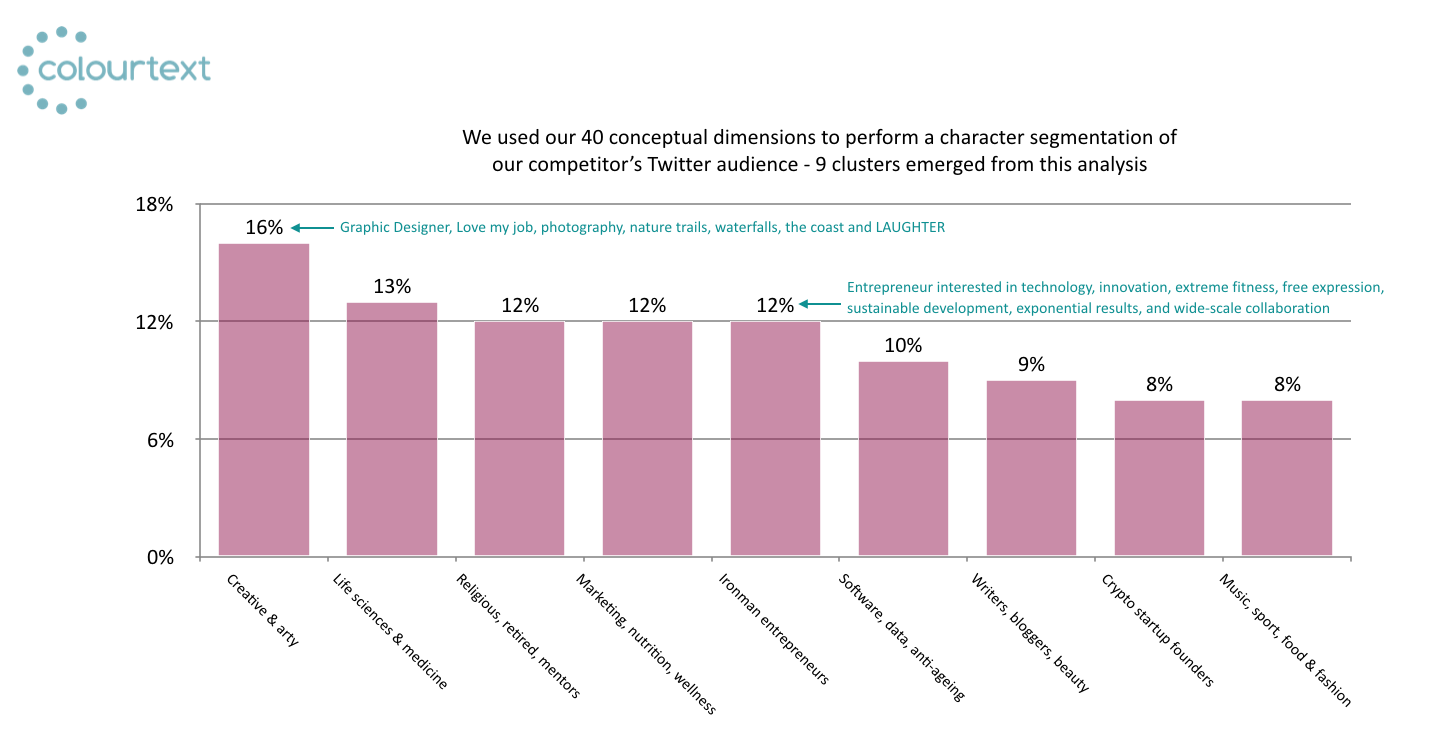
The largest group in this emerging market sector (16%) are "Creative & arty" types. A typical self description for this group reads, "Graphic designer, love my job, photography, nature trails, waterfalls, the coast and LAUGHTER".
My personal favourites are the "Ironman Entrepreneurs" - this group seem so clear to me. 80% are men, 8% live in the SF Bay Area and a typical self-description goes like this, "Entrepreneur interested in technology, innovation, extreme fitness, free expression, sustainable development, exponential results, and wide-scale collaboration".
Our client now feels much more confident about who these early adopters are, where to target them with advertising and what they need to hear to consider switching brands. If you'd like to discuss how we could use Twitter data to identify and build-out a segmented audience for your brand please drop us an email and we'll get right back to you.