"Colourtext always take a fresh approach to discovering hidden patterns in data. Whether you want to conduct segmentation or mine your CRM for deep insights, they will help you see your customers , and what they are seeing , in new ways."

When the word count gets really big, words stop behaving like words and we have to begin treating them like numbers.
Quant Semiotics is a data analysis and segmentation methodology that combines computational text analysis and complex network analysis to segment a wide range of quantitative and natural language datasets.
Quant Semiotics is a useful tool that gives us the capability to analyse, at enormous scale, the network of relationships that bind together structurally significant concepts (represented by multi-word keyword combinations) within vast repositories of text-based data. Here are two public domain case studies that apply Quant Semiotics to the Skincare Sector and Media & Market Research Industry.
It's important to appreciate from the get-go we're talking about *really big* datasets because scale is a crucial factor here. Sources like focus group transcripts or open-ended responses from market research surveys are relatively small in terms of word count. The best way to analyse this kind of data is to use traditional, largely manual approaches like semiotics that use qualitative frameworks.
But when the word count gets really big, words stop behaving like words and we have to begin treating them like numbers. This is when Quant Semiotics comes into its own, hence the name. It's a great way to find the insights in huge amounts of web or social content that no lifetime will be long enough (or dull enough) to read though, like the comments for a viral YouTube video that form the basis of the image below.

Quant Semiotics leans heavily on complex systems theory (a branch of information theory - see Claude Shannon) that analyses bodies of text as networks of interconnected elements. In very large datasets with huge word counts almost all information lies in the topological and statistical distribution - the pattern - of interactions of keywords within the data. You can see this kind of network visualised in the images above.
At massive scale the meaning of individual words and their immediate context becomes much less important than the statistical dynamics of their combinations. This feels very counter-intuitive to Qualitative researchers or anyone experienced in essay-based subjects and literary studies. However, it's nonetheless true and leads to insights that are inaccessible to conventional methods of interpretive analysis.
The Quant Semiotics process
Quant Semiotics gives us the capability to analyse, at enormous scale, the network of relationships that bind together structurally significant concepts (represented by multi-word keyword combinations) within vast repositories of text-based data.
The process begins by using Natural Language and Semantic Analysis techniques to identify significant ideas and concepts within huge collections of web content that reflect a specific market sector or cultural theme.
For instance, we might gather decades of news articles that cover a specific industry. We applied this approach to our own industry, the Media & Market Research industry, by collecting 29,000 MRWeb.com articles stretching from 2005 to 2021.

We might also begin with a detailed SEO-style keyword analysis of content on the web that reveals the most frequently searched keyword queries relating to a specific topic or theme. This gives us a detailed view of the 'demand side' of a market - what consumers ask most frequently and want to know the most.
We then use this data to capture content from the top-ranking page URLs for each keyword in our list, which can number many thousands of pages in aggregate. This reveals the most popular online content that reflects user need across a wide range of topics or themes and thereby represents the 'supply side' of the skincare market.
We thereby use the questions people ask most frequently about skincare issues and products to find the web content that best reflects personal aspirations and broader consumer demand. Our Quant Semiotics meets Skincare case study is a great example of this approach.
Either method generates a huge amount of market-relevant data that we can crack open using Natural Language and Semantic Analysis techniques. This lead to identifying the strucutally significant ideas and concepts at play within the content we have collected.

For instance, suppose we collect a database of 20,000 web articles weighing in at 8 million words. That's a big dataset. All that text is likely to contain something like 85,000 distinct words and multi-word combinations. Quant Semiotics deploys a semi-automated / semi-curated semantic analysis process to grade each distinct word in order to pinpoint a special group of (for example) around 700 keywords that are uniquely capable of characterising a specific market and the things it talks or thinks about.
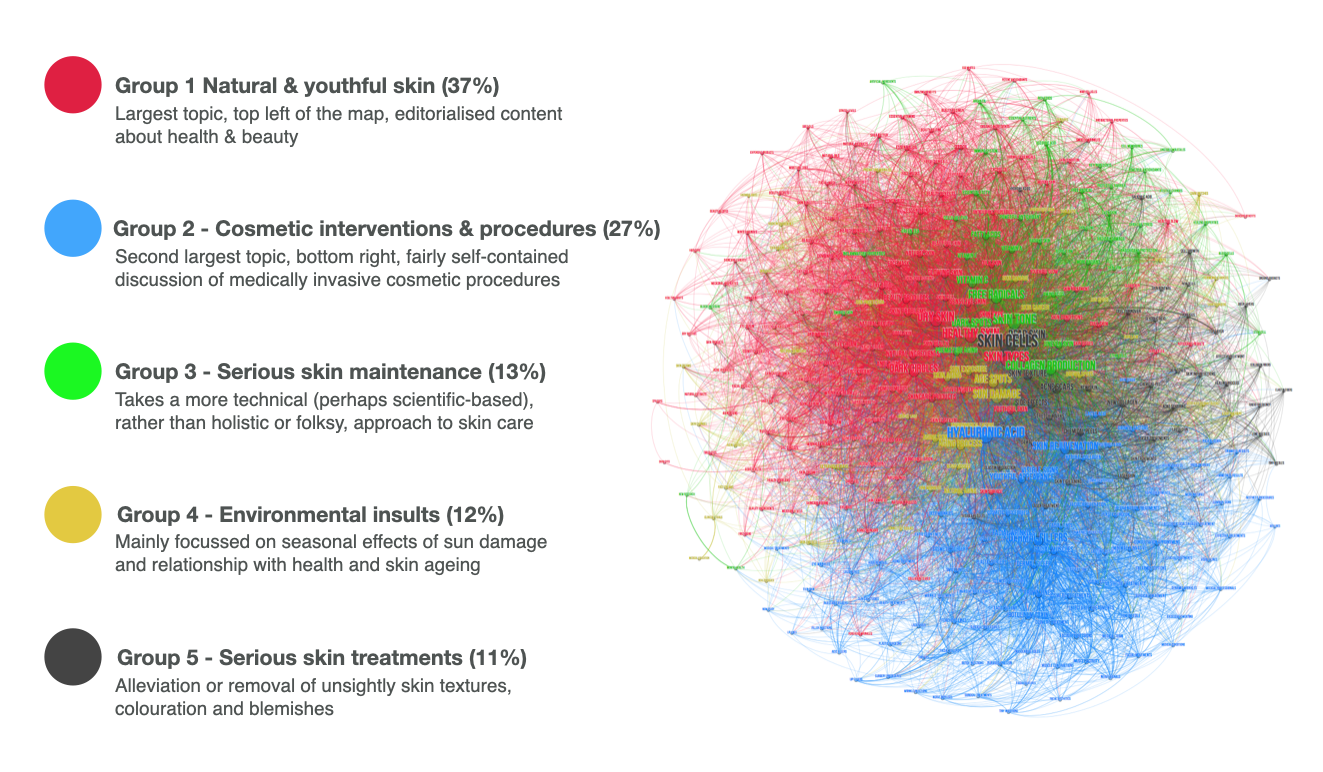
Finding those keywords is crucial for the next step in the Quant Semiotics process. The keywords are used as inputs for a network analysis that identifies the topological structure of keyword relationships within the dataset. From this emerges a network-based content segmentation that naturally divides all of the collected content into the emergent topical components that reflect key themes and memes within the target market sector.
To talk about applying Quant Semiotics to your brand or market contact us now.